Biography
I’m a deep learning enthusiast with a background in research, engineering, and management. My work blends these areas to drive AI innovation.
- Deep Learning
- High Performance Computing
- Python, Rust, C/C++
PhD in Computer Science, 2015
The University of Tokyo (received Dean's award; finished in 2 years)
M.S. in Computer Science, 2013
The University of Tokyo (received Dean's award)
BSc in Artificial Intelligence, 2011
The University of Tokyo
Experience Summary
Engineering
It has been 20+ years since I started computer programming. I am the original founder of OSS ML software packages such as Optuna and ChainerMN, and ranked among the top 10 in global coding competitions such as TopCoder and Google Code Jam.
Research
I am enthusiastic about working on a wide range of problems, whether they are specific to a company or real-world issues, as well as those that are of academic interest. I have co-authored papers that have been published at top-tier academic conferences (see DBLP and Google Scholar).
Management & Leadership
My experience includes various types of management and leadership, such as leading without formal authority, serving as an engineering manager for a team, and being responsible for a group of teams consisting of 20+ SWEs.
Speciality Summary
Machine Learning (2016-present)
With 7+ years of industrial experience in ML, particularly in DL, I have extensive experience in research, building production models, and designing software packages. I am a Kaggle Grandmaster. I have co-authored papers that have been published at prestigious conferences such as NeurIPS, CVPR, and KDD. I am the creator of OSS ML software packages such as Optuna and ChainerMN. I have co-authored ML books on Kaggle and Optuna.
Algorithms and Data Structures (-2016)
I was an enthusiastic competitive programming player and achieved a maximum TopCoder rating of 3292, which was 4th in the world at that time. I have won a bronze medal at ACM ICPC World Finals 2012 and 9th place at Google Code Jam 2010. My papers on algorithms and data structures were published at SIGMOD, CIKM, WWW, AAAI, KDD, ICDM. I have co-authored a Japanese book on algorithms for competitive programmers, which has been translated and published in Korea, China, and Taiwan.
Experience
Engineering Projects
![]()
I proposed the development of a new framework for hyperparameter optimization, Optuna, and performed the design and initial implementation. I also established and managed the development team.
Optuna offers several unique features that previous frameworks lacked. These features include a flexible “define-by-run” style search space description and a combination of sampling and pruning for efficient optimization. Additionally, it boasts scalability for large-scale distributed optimization, as well as simplicity, allowing users to easily experiment with optimization. Optuna has been widely adopted in internal projects and is also enthusiastically supported as open-source software outside the company. Its GitHub repo has garnered 7.3K stars, and its KDD’19 paper has been cited 1.8K times.
Takuya Akiba, et al.: Optuna: A Next-generation Hyperparameter Optimization Framework. KDD 2019. (arxiv)
![]()
I have conducted basic research on distributed parallel deep learning, and established a methodology. Then, I designed and implemented ChainerMN, which adds distributed training feature to Preferred Networks’ deep learning framework Chainer.
Back in 2016, the question of whether deep learning could be effectively parallelized on a large scale remained unanswered, with only a variety of papers and prototype implementations available. I examined these sources closely, formulated my own hypothesis, conducted experiments to establish an efficient methodology. In particular, despite async SGD being considered by many as the preferred approach at the time, I recognized early on that sync SGD could be better suited for certain tasks, such as image classification, and made it a priority to implement that method. This decision has since proven to be correct, as sync SGD is now much more widely used than async SGD. This decision of mine gave Chainer and ChainerMN a significant advantage in the scalability race for deep learning frameworks during that period.
Following this success, the HPC field became a team, and I was assigned to lead the team. In addition, the company was steered in the direction of greatly increasing computing power by building supercomputers (MN-1, MN-2, and MN-3) and dedicated ASICs called MN-Core.
Takuya Akiba, et al.: ChainerMN: Scalable Distributed Deep Learning Framework. Workshop on ML Systems at NIPS 2017. (arxiv)
Seiya Tokui, et al.: Chainer: A Deep Learning Framework for Accelerating the Research Cycle. KDD 2019. (arxiv)
Research Projects
I launched the PFDet project, assembled a team of six researchers and engineers, and led the project to success.
The goal of the PFDet project was to find ways to effectively utilize large-scale distributed deep learning for tasks such as object detection and instance segmentation, and to build a practical system for these tasks with ChainerMN. At the time, large-scale distributed deep learning was still in its infancy, and the methodology had not yet been established for more complex tasks such as object detection. We participated in a contest for Open Images, a massive object detection dataset, and successfully used 512 GPUs to train the model. Our model achieved the second-highest accuracy at the time. The PFDet model and system were used in internal projects.
Takuya Akiba, et al.: PFDet: 2nd Place Solution to Open Images Challenge 2018 Object Detection Track. Open Images Challenge Workshop at ECCV 2018. (arxiv)
Yusuke Niitani, et al.: Sampling Techniques for Large-Scale Object Detection from Sparsely Annotated Objects. CVPR 2019. (arxiv)

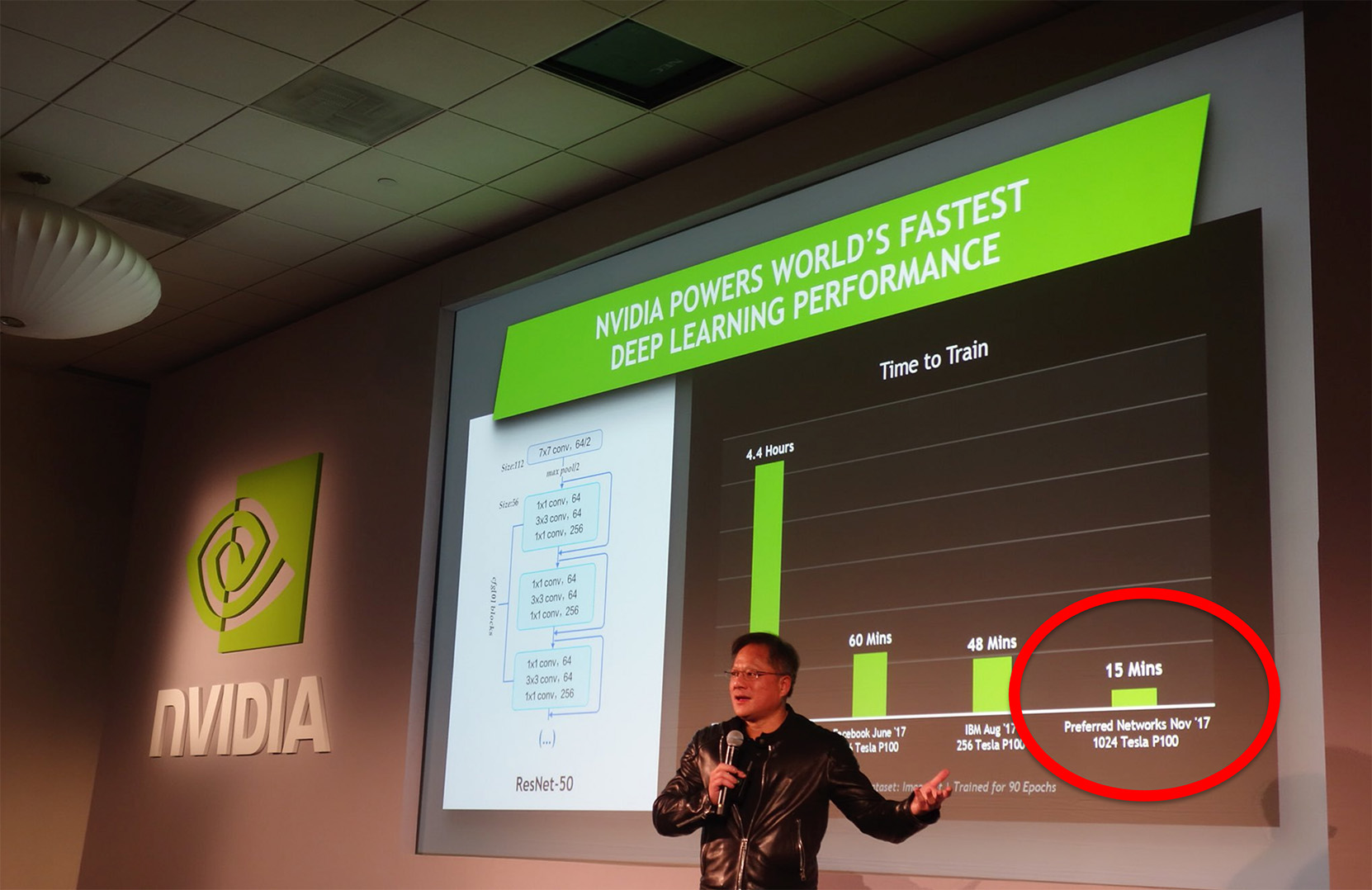
I proposed the challenge of training ResNet50 in 15 minutes using 1024 GPUs with ChainerMN, and led the team to successfully complete this challenge. This was the world’s fastest record at the time.
In order to showcase the effectiveness of ChainerMN and identify any potential limitations for future research and development, I believed it was necessary to conduct ultra-large scale parallel experiments. Facebook Research had previously set a record of 1 hour using 256 GPUs for training ResNet-50 on ImageNet. However, we surpassed this achievement by completing the task in a record-breaking 15 minutes using 1024 GPUs. As deep learning with 1024 GPUs were unprecedented at the time, it required significant effort to get things working properly, even including debugging middlewares from other companies and addressing hardware failures.
Takuya Akiba, et al.: Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes. Deep Learning on Supercomputing Worskhop at NIPS 2017. (arxiv)
I formed a team and participated in the NIPS 2017 Adversarial Attack Competition. I devised a new method based on large-scale distributed deep learning, which was fundamentally different from the mainstream methods.
The mainstream method for adversarial attacks had been to perform backpropagation on the input image, calculate the gradient, and use the gradient to modify the image. I proposed a method of learning a CNN that is trined like a generative adversarial network (GAN), which takes an original image as input and outputs an adversarial example. I used 128 GPUs and ChainerMN to train this CNN, using both data parallelism and model parallelism.
Takuya Akiba, et al.: Non-Targeted Attack Track 4th Place Solution. Competition Workshop at NIPS 2017. (poster)
Alexey Kurakin, et al.: Adversarial Attacks and Defences Competition. The Springer Series on Challenges in Machine Learning. (arxiv)


Publications
Papers
For the full list, please see DBLP or Google Scholar.
- Ken Namura, et al. (26 authors): MN-Core - A Highly Efficient and Scalable Approach to Deep Learning. VLSI Circuits 2021: 1-2.
- Yusuke Niitani, Takuya Akiba, Tommi Kerola, Toru Ogawa, Shotaro Sano, Shuji Suzuki: Sampling Techniques for Large-Scale Object Detection From Sparsely Annotated Objects. CVPR 2019: 6510-6518.
- Mitsuru Kusumoto, Takuya Inoue, Gentaro Watanabe, Takuya Akiba, Masanori Koyama: A Graph Theoretic Framework of Recomputation Algorithms for Memory-Efficient Backpropagation. NeurIPS 2019: 1161-1170.
- Seiya Tokui, Ryosuke Okuta, Takuya Akiba, Yusuke Niitani, Toru Ogawa, Shunta Saito, Shuji Suzuki, Kota Uenishi, Brian Vogel, Hiroyuki Yamazaki Vincent: Chainer: A Deep Learning Framework for Accelerating the Research Cycle. KDD 2019: 2002-2011.
- Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, Masanori Koyama: Optuna: A Next-generation Hyperparameter Optimization Framework. KDD 2019: 2623-2631.
Books










Competitive Programming
Kaggle
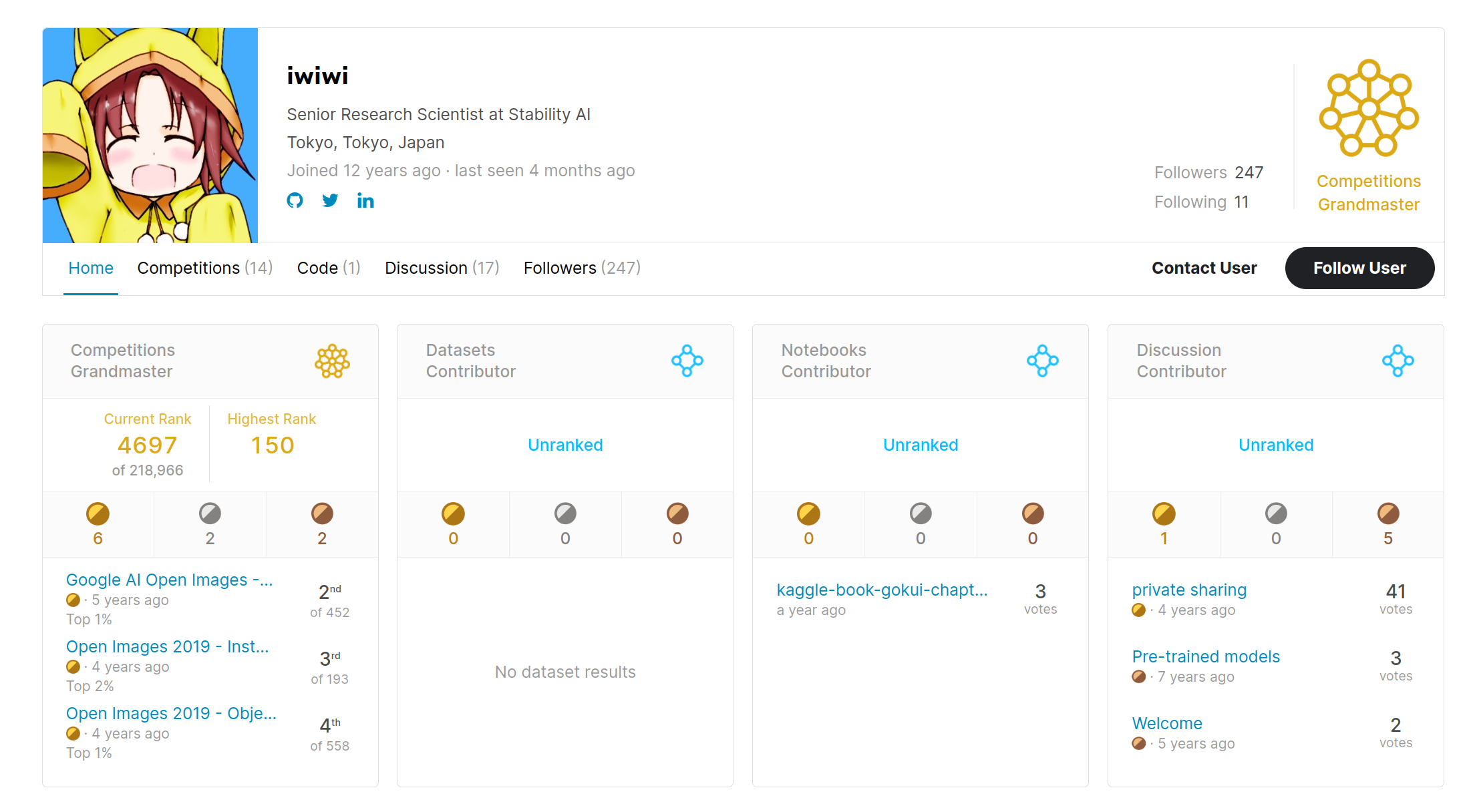
I started Kaggle in 2016 and became a Kaggle Grandmaster in 2019. I mainly participated in deep learning contests, earning six gold medals, including one solo gold medal. My Kaggle profile is here.
Algorithms
I started competitive programming in high school and participated in algorithm contests for nearly 10 years. Below are my results in the on-site finals of major world competitions.
| Year | Contest | Location | Rank |
|---|---|---|---|
| 2014 | Google Code Jam | Los Angeles, USA | 15th place |
| 2013 | ICFP Contest | Massachusetts, USA | 1st place |
| 2013 | TopCoder Open | Washington DC, USA | 10th place |
| 2012 | TopCoder Open | Orlando, USA | 4th place |
| 2012 | ACM ICPC | Warsaw, Poland | 11th place |
| 2012 | VKCup | Saint Petersburg, Russia | 34th place |
| 2012 | Facebook Hacker Cup | San Francisco, USA | 9th place |
| 2011 | TopCoder Open | Fort Lauderdale, USA | 7th place |
| 2011 | ICFP Contest | Tokyo, Japan | 2nd place |
| 2010 | Google Code Jam | Dublin, Ireland | 9th place |
| 2009 | TopCoder Open | Las Vegas, USA | 9th place |
| 2008 | TopCoder Open | Las Vegas, USA | 17th place |
| 2008 | Google Code Jam | Mountain View, USA | 59th place |
Back then, TopCoder was the most active platform for competitive programming. I participated in 172 TopCoder contests, and my highest rating was 3292 (as of April 1, 2013), which ranked me 4th among tens of thousands of participants in the world at that time.